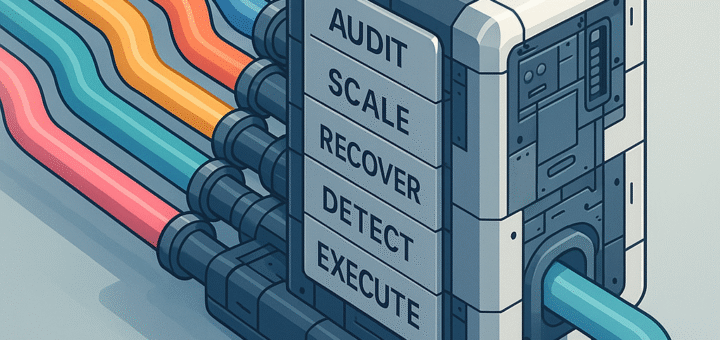
The following are core principles I use for implementing data integration / logistics (‘ETL’). This is a component (design pattern) from the Data Solution Framework repository, specifically this pattern. The purpose of this pattern is to define a set of minimal requirements that every single data logistics process (i.e. procedure, mapping, module, package, data pipeline) should conform to. These fundamental guidelines direct how all data integration processes should behave under the architecture of the Data...
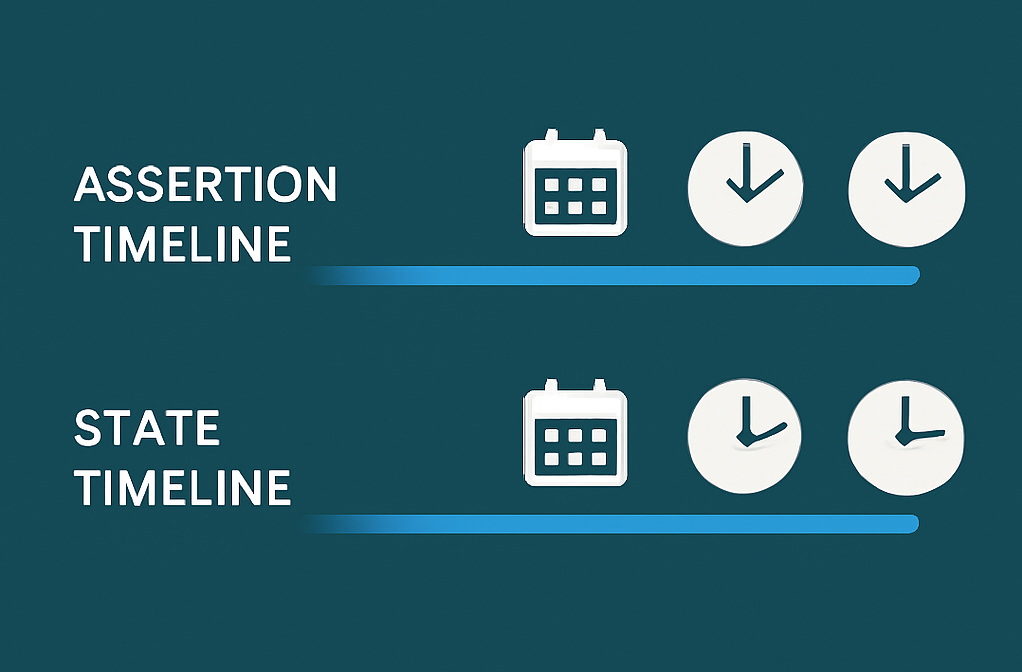
To future-proof your data solution, consider implementing both a technical and business timeline from the start, so you have flexibility when data maturity increases.
We (Stefan Johannsson and myself) have just completed the work on the next version of the DIRECT framework. Now available on Github! DIRECT v2.0 is a comprehensive overhaul of this widely adopted framework for data logistics process orchestration, serving as the ‘control framework’ of the data solution. Significant improvements have been made, legacy SSIS artifacts have been removed, and the framework has been tested on on-premise systems as well as Azure SQL Family databases and...
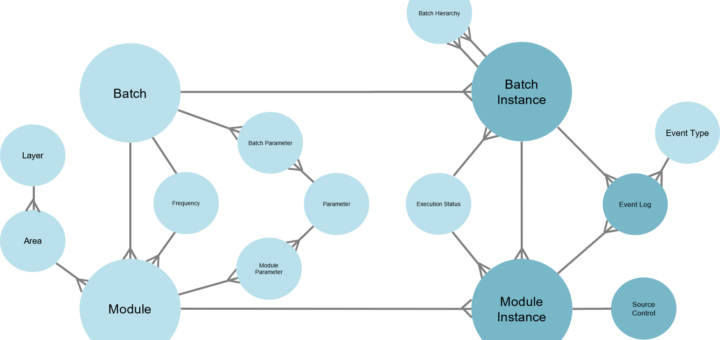
The latest version of the schema for data solution automation has been published on Github. This comprehensive collection includes examples, functions, and definitions crucial for metadata management in data solutions, particularly data warehouse systems. You can find the details, code, and documentation here: What has changed? One significant update focuses on the Business Key Definition. Initially, it featured a property called ‘Business Key Component Mappings,’ which listed data item mappings for various business key components...
Data Engine Thinking – the book by Roelant Vos and Dirk Lerner – provides a full and in-depth overview of everything you need to develop a data solution that can stand both the test of time and the real world.
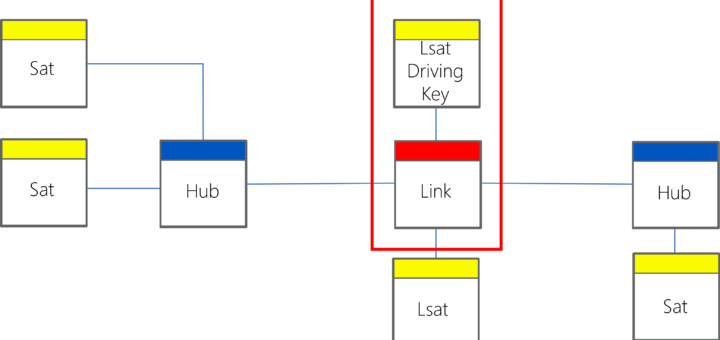
End dating Satellites in Data Vault has much more than meets the eye. This post lays out various options and consideration that may help decide whether to implement end-dating, or not.
I would like to share this short blog post with an overview of everything that is happening the data solution automation space. First of all, it’s only a week to go before heading to Europe for various things, including: Working towards these events always pushes the overall content, and there is a lot happening. The design/mapping metadata tool TEAM and code-generation tool VDW are getting a facelift and are being updated to use the v2.0...
The updated (v2.0) version of the data automation metadata schema has been finalised! This version is\ the culmination of many discussions over a long period of time, and hopefully is a step in the direction of making the exchange of data solution / data warehouse metadata easier. The link to the latest & greatest version is here: https://github.com/data-solution-automation-engine/data-warehouse-automation-metadata-schema/releases/tag/v2.0. An important change is that the ‘Data Query’ concept has been split out into a query at...
Follow:
Search this site
More
Upcoming Events
Moving to Europe (The Netherlands) - July 17th, 2025