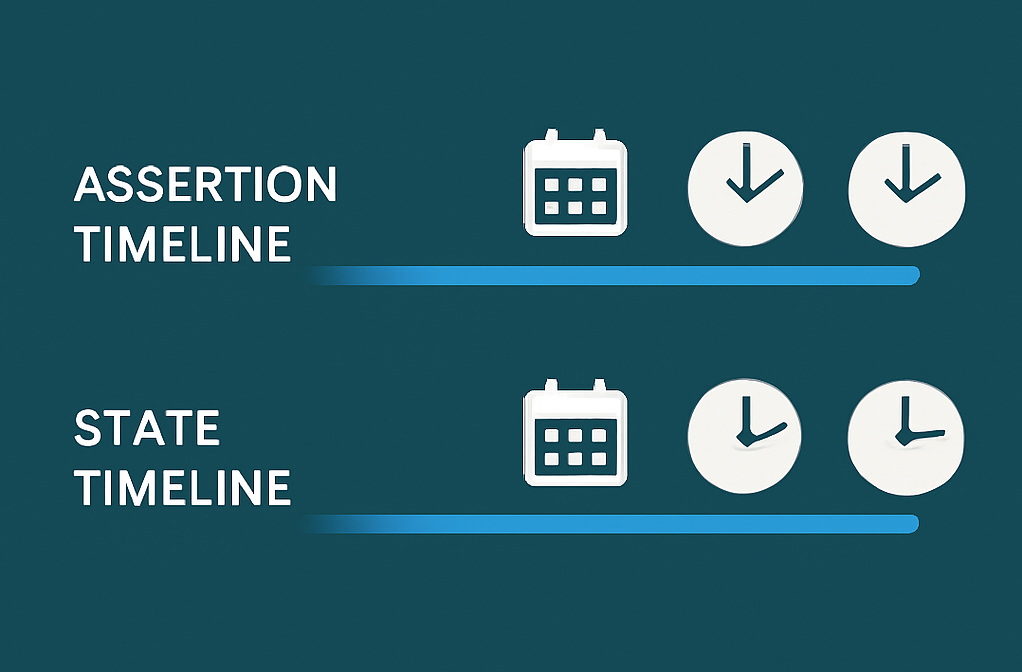
Guidelines for Data Integration Processes
The following are core principles I use for implementing data integration / logistics (‘ETL’). This is a component (design pattern) from the Data Solution Framework repository, specifically this pattern. The purpose of this pattern is to define a set of minimal requirements that every single data logistics process (i.e. procedure, mapping, module, package, data pipeline) should conform to. These fundamental guidelines direct how all data integration processes should behave under the architecture of the Data...