
How to agree to disagree (on data warehouse automation)
This is a verbatim of my presentation at Knowledge Gap 2021, about ways to collaborate on data warehouse automation.
In this presentation, I present the ideas and application of a schema that can be used to interface metadata between and across different delivery tools. Essentially, how we can use a generic schema to separate what we can agree on with what we don’t – and through this support all known data warehouse use-cases across different modelling techniques, patterns, and tools.
There is also a video available, either directly on YouTube or in the videos page on this blog. The repository covering this is found here on Github.
How to agree to disagree
There must be 1000s of code generation tools, scripts, accelerators, vendor platforms or tool add-ins focused on speeding up data warehouse delivery. Excel, SQL, code, more Excel. In fact, I only know a few people who have not been working on a tool of their own to use in their projects.
Delivering a good data solution, such as a data warehouse, is difficult and requires various concepts to play well together, and to be implemented correctly. With so many tools we have so many variations of the same theme, and some are better than others – or at least in certain areas. I am not sure we are always doing our projects, customers, and ourselves a favour by introducing yet another custom solution.
Developing data warehouses is not always easy. There are many options to evaluate, considerations to make, and frameworks to apply. When we design and deploy a data solution, we aim to integrate all these concepts and frameworks into a working coherent deliverable which ideally does everything as intended and also does it perfectly.
At the same time, we often work independently and in parallel on these complex topics – even when the projects we do can be very similar in nature. There has to be a way to exchange the common parts of our work, the design metadata, so that we can continue to make delivering data solutions easier and better, while everyone still gets to use the tools they like and are familiar with.
Design metadata is the information you need to generate your solution. By using such an approach, you may be able to save time re-inventing the wheel in various cases. At the same time, we can still continue to work with the same tools and patterns that we prefer.
Using an agreed format to exchange design metadata helps to allow you to focus on your core strengths. Some solutions have really great metadata management features, some are strong in modelling, some generate great code and some have really good control frameworks or conventions.

You may think, how can any generic schema be sufficient to store all the complexity I have in my solution; all the metadata I need to support my frameworks and automation? Actually, in most cases there is a ‘core’ of design information that is consistent across projects.
For example, in all cases data can go from A to B, or it is interpreted this way using a view or transformation (which I consider the same in this context). After various workshops and projects the schema is pretty stable, and it can always be adapted. There is also a concept of key/value pair extensions that was able to solve all specific requests so far without concessions made.
The approach is not tied to any specific technology or data modelling approach, and would support design metadata to build Dimensional Models, Data Vault, Anchor or 3NF. There is not anything that prevents a certain solution direction, and it’s up to you which parts you use and how you use them. In principle it’s also possible to relate different models together – for example, a mapping between conceptual to logical models.
If you are currently using a repository, that is compatible too. It’s relatively easy to write an adapter that can interface with a schema such as this. The added advantage is that the metadata can be stored in Json format, which is text based and easy to version control and share. This is usually easier than merging version in a database and lends itself well to DevOps. At the same time, having a separate artefact to merge into a repository is made easier by having a dedicated change file to process.
In some cases, the available automation tools work somewhat like a black box – sometimes requiring all data processing to be done internally behind the scenes. This sounds convenient, and it can be, but it also can force a lock-in using a concept, approach, or technology that you may not like as much. All is usually OK unless you want something different, and we’re still figuring things out in some areas.
Sometimes, these accelerators can be seen (usually by their creator – and I’m one of them) as worthy of strict IP protection.
Personally, I think the magic of automation is not really in the code generation but in the way we manage our design metadata. So let’s dive into the details.
Unboxing data warehouse automation
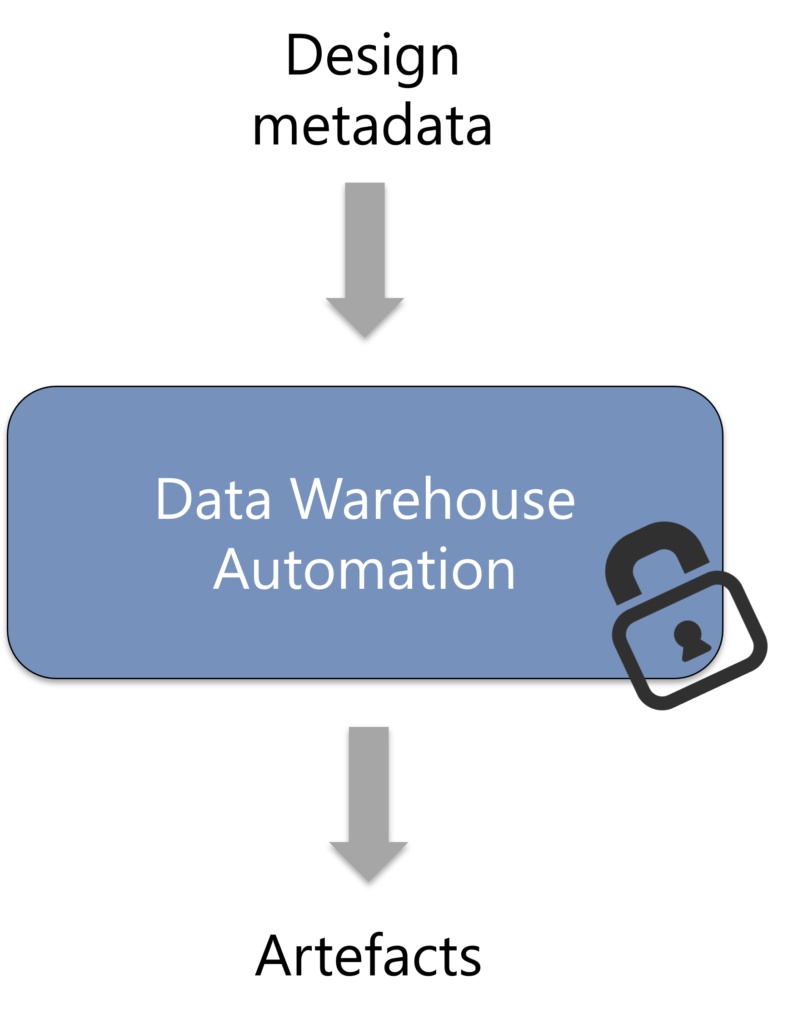
If you consider data warehouse automation as a black box, then the design metadata goes in and data logistics processes (artefacts) are generated and operated from there in some shape or form.
The idea behind the schema for data warehouse automation is to separate the management of the design metadata from its storage. Design metadata is the information you need to generate the files or database structures and the data logistics to interact with them.

Some tools do more than others, and often they do many things and have lots of knowledge embedded. From the perspective of metadata we can limit this to managing the design metadata, storing it, interfacing with it and applying some patterns against it for code generation. This is a separation of the way we work with the metadata from the way we store it and the way we use it.
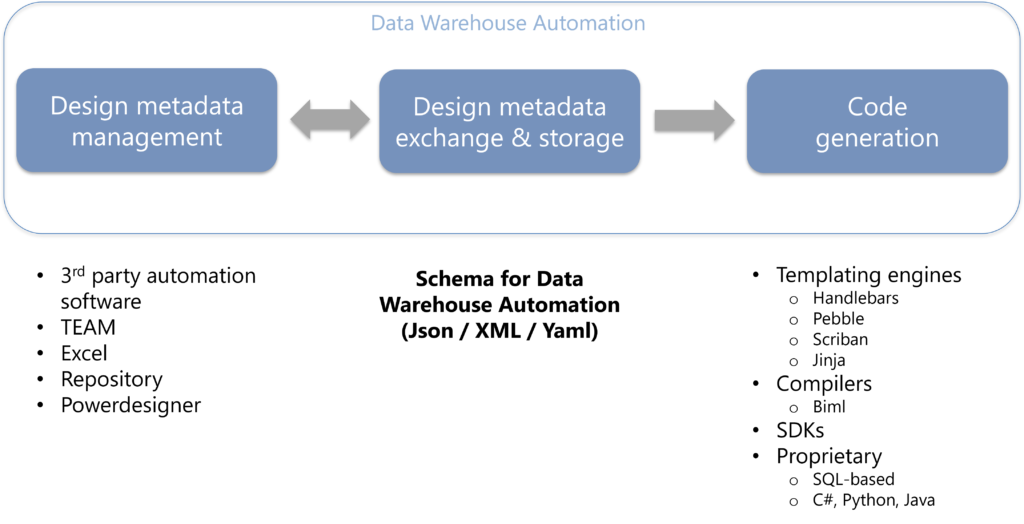
When we look at it like this, we can start applying different technologies. For example, we could potentially use any tool we like to interact with the metadata. We can use our Excel sheets, our 3rd party software, our homebrew (TEAM) or our favourite modelling tool. It doesn’t matter, because we read from and write to the same format.
We don’t need to align on technology to do our design, but we can work together on how we want to use this design metadata to deliver outputs. he same applies to design decisions on the ‘best’ way to deliver certain patterns. Do we need caching, do we need a lookup, do we need ETL or ELT?
We don’t need to agree on this. If we do, then great and if not we can just let the meritocracy play out. The design metadata is independent of this.
Data Objects, Items and Mappings
The schema for data warehouse automation is an open source project on Github. It has a number of components, such as a schema definition, documentation, a class library, some example metadata and patterns (in Handlebars) and a validation project.
The schema definition is a Json schema definition, which lists out the specifics of each segment. As a Json file, it can be consumed in various ways – some of which are explained in the project on Github.
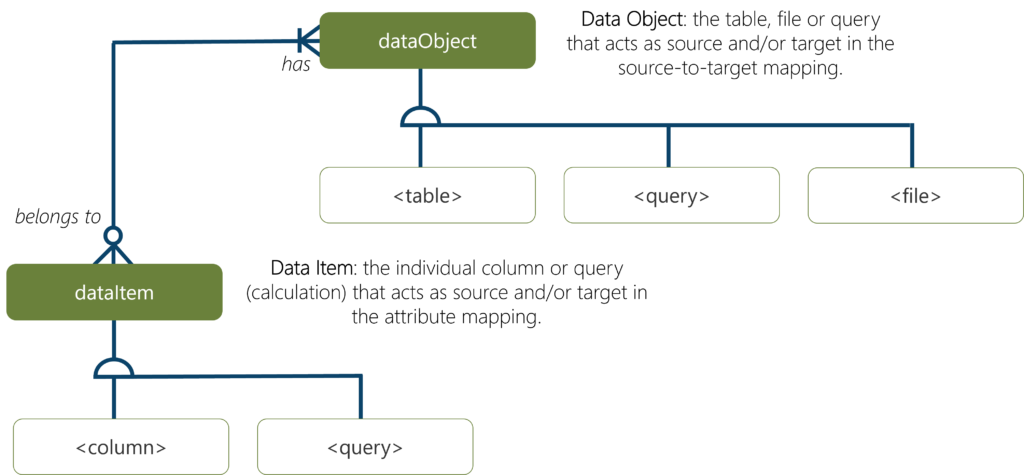
The schema defines what I refer to as a Data Object, which can be a file, query, table or container. Whatever it is. A Data Object can have Data Items, which can be attributes or queries again.
In a simple implementation a Data Object is a table and a Data Item is a column, and you can have mappings between one Data Object to another as well as for their Data Items.
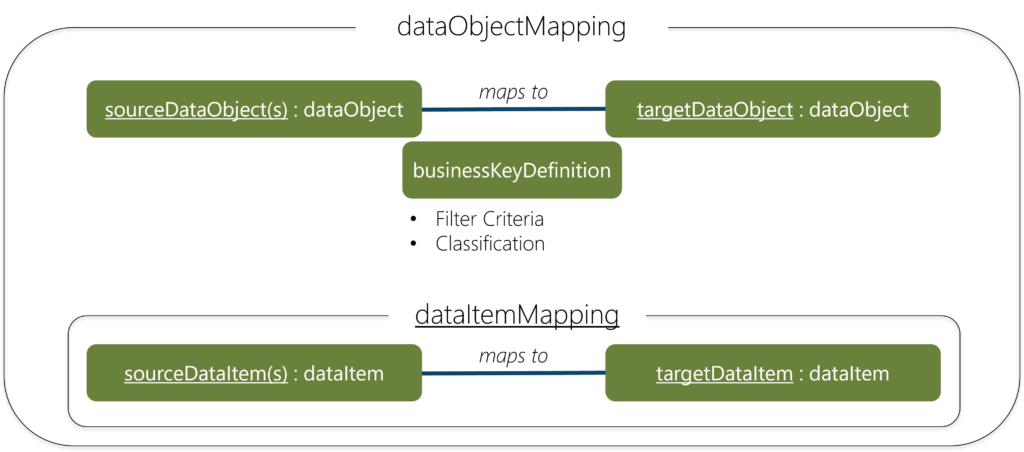
This mapping between on Data Object and another is a Data Object Mapping.
It brings together a source Data Object to a target Data object with some properties (such as the classification and filter criteria displayed) and optionally includes a lower-level Data Item Mapping as well. In practical terms, the Json definitions from the schema are instantiated as it they were classes in traditional object oriented programming.
The result is a very easy and practical way to create all kinds of data structures, data logistics or transformations ranging from very simple to extremely complex.
I have prepared a few examples of text-based code generation using this approach on Github, but it works the same way if you’re using SDKs, APIs or 3rd party compilers such as Biml.
Need more?

One feature I would like to highlight is way you can attach an extension to each definition, at every level. If there’s something specific you need, you can always create an extension for this. This is basically a key/value pair with a description, and it can be applied everywhere.
Let’s work together!
This is a high level introduction of why a schema for data warehouse automation could make sense, and how it works. This schema can facilitate collaboration without forcing us into a certain solution or technology corner. It an open source project on Github that includes documentation, a class library, a validation technique and various regression testing scripts and samples.
The schema works by separating design metadata management from storage, and provides a simple and flexible way we read from, and write to, design metadata. If you have an automation tool, or are developing one, please have a look at what is already available and how we can work together.
If you don’t, you may miss out on connecting your solution to other frameworks and evolving concepts. However, if you do, you may find you can focus on your specific area of interest, your strength, more because some of the other necessary concepts can be reused.
I genuinely feel that approaches such as these are in the best interest of ourselves and the projects we deliver. If we can at least agree on the basics, we don’t have agree on the way we use the design metadata. That will work itself out naturally. We do not have to agree on the best way to implement x, y or z – we can discuss and let the meritocracy play out. But at least we can hopefully agree that fundamentally we are all mapping data from A to B somewhere.

