
Investigating code generation for Delta Lake using Azure Data Factory
Introduction – back in code generation mode
Things have been busy after joining Varigence a few months ago. A major focus has been to develop new code generation features, to enable the BimlFlex data warehouse automation platform to use Azure Data Factory (ADF) Mapping Data Flows (‘Data Flows’)- in particular to interfacing with Delta Lake storage.
Basically, to make sure that we can use BimlScript to generate Delta Lake compliant Data Flows and integrate this with the framework to manage the design metadata (‘BimlFlex’).
While much of this is still in development, and will be part of the BimlFlex product, there are aspects that are worth sharing in the community context also. Hence this post.
I will also be more active on the Varigence blog, to elaborate on features that are more relevant if you’re interested in the BimlFlex product for data warehouse automation – and how you can generate these solutions from there.
What is Delta Lake, and why should I care?
Delta Lake is an open-source storage layer that provides transaction control (Atomicity, Consistency, Isolation and Durability, or ‘ACID’) features to a data lake. As such, Delta Lake can be configured for example for Azure Data Lake Gen2 or as part of a Databricks cluster.
This supports a ‘Lake House’ style technical architecture, which is gaining interest because it offers possibilities to work with various ‘kinds’ of data in a single environment. This means various use-cases can be supported by a single infrastructure. For example, combining semi- and unstructured data or batch- and streaming processing.
Microsoft has made Delta Lake connectors available for ADF pipelines and Data Flows. Using these connectors, you can use your data lake to ‘act’ somewhat as a relational database for delivering your data warehouse target models while at the same time use the data lake for other use-cases. That’s the concept.
Working with Delta Lake, on Azure
In Azure, you can interface with a Delta Lake in various ways depending on the data integration approach. At the time of writing, ADF Execute Pipelines and associated activities can connect to a Delta Lake as a source or a sink. This is done by creating and assigning a ‘Dataset’ of the type Delta Lake.
Herein lies the difference in approach, because a Dataset in Azure is a specific reference to a, well, set of data that you want to interact with. A table or file for example. Although this can be parameterised for reuse (see this post for similar concepts) the idea is to create a Dataset for a specific data object.
You can also take a different approach and use Data Flows to connect to Delta Lake. This way, you can choose between connecting to your data via a Dataset reference (as with ADF pipelines) or you can use an inline dataset with a Delta Lake connection (displayed below).

There is a significant different between these approaches. If you use a Dataset to connect to Delta Lake, this requires an existing platform to be available – such as for example a Databricks cluster with Delta Lake configured.
If however you are using the inline feature, which is only available in Data Flows, you can use the Delta Lake connector without requiring a separate cluster that hosts Delta Lake. At runtime, ADF will spawn an integration runtime that provides the compute.
This means you can use Delta Lake without actually having a cluster available. This inline mechanism also supports various other connectors, not just Delta Lake – but it’s a good example.
This makes it possible to configure an Azure Storage Account (Azure Data Lake Storage Gen2) and use the Delta Lake features without any further configuration.
Every time you run a one or more Data Flows, Azure will spin up a cluster for use by the integration runtime in the background and read/write data to the storage account.
How can I get started without configuring a Delta Lake cluster?
Creating a new Delta Lake to try things out is easy. The quickest way to have a look at these features is to create a new Azure Storage Account resource of type Azure Data Lake Storage Gen2.
For this resource, the ‘Hierarchical Namespace’ option must be enabled. This will enable directory trees/hierarchies on the data lake – a folder structure in other words. It is a requirement for Delta Lake to work on Azure.
Next, in ADF, a Linked Service must be created that connects to this Azure Storage Account.
When creating a new Data Flow in Azure Data Factory, this new connection can be used as an inline data source with the type of ‘Delta’ – as per the screenshot provided earlier.
This is all that is needed to begin working with data on Delta Lake.
Within the storage account, each container acts as ‘database’ and each directory/folder as ‘table’. For example:

If we look into one of these ‘tables’, for example the ‘Hub_Account’, the similarities with a database appear to stop:
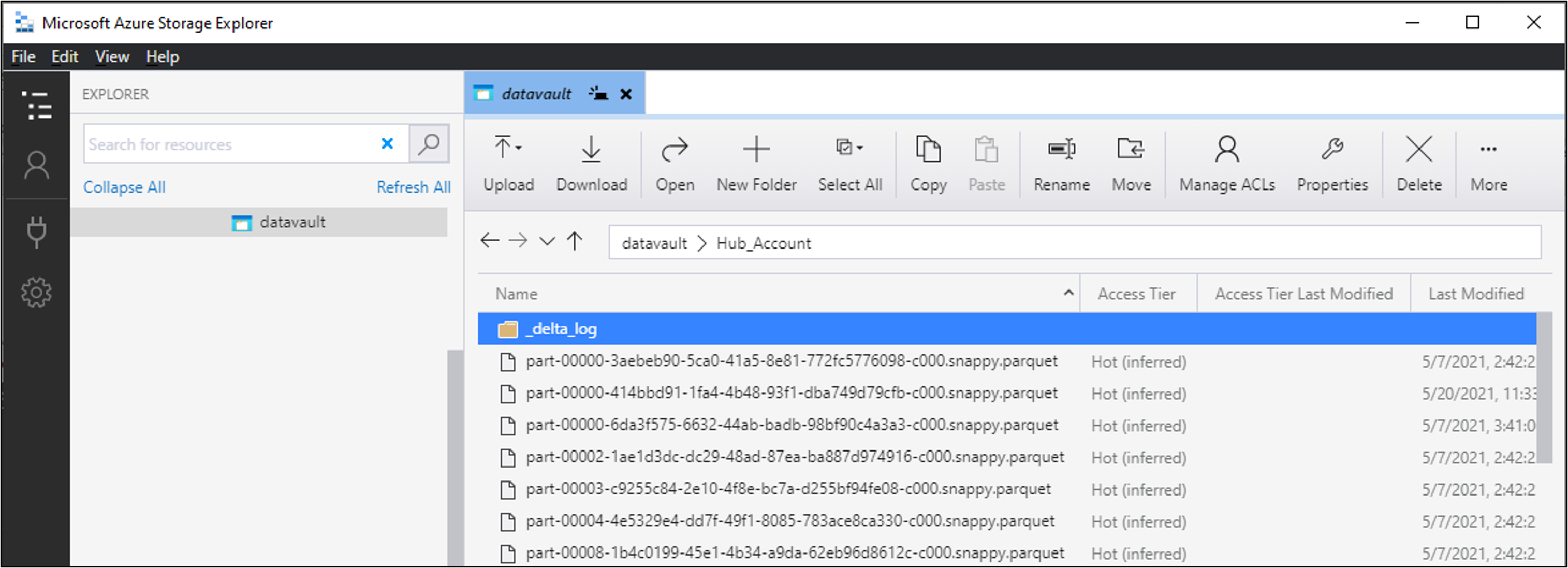
The contents are actually following Delta Lake protocol, with the combined files representing the table. The _delta_log directory contains the transaction log for the Delta Lake – the key feature to support ACID.
Even though files can be individually downloaded and opened, for example using a tool such as Parquet Viewer (assuming the files are in Parquet format), each file only contains a few records out of the logical table.
Thankfully, it is easy to create a separate Data Flow to connect to this directory/table, using the inline function, and writing the data to traditional database such as SQL Server. This is just to test and show that it all works as expected.
In next posts, it may be interesting to go into more detail on what the patterns look like using this inline function. The benefit of not running a separate cluster has been mentioned, but using inline sources also means you can’t push down code (SQL) to the underlying infrastructure.
For example, this means you can’t modify a SELECT statement – and you have to implement an alternative in the Data Flow.
And, if you already have a cluster available you may want to use this investment for compute also. Tests already proven that it’s possible to access these areas via Databricks (using CREATE TABLE USING DELTA) as well as via ADF.
Either way, we are working to make sure the Biml language can do both and that we have a framework to deliver these different technical implementations using the same metadata.
We’re already quite advanced making it work, and while some effort is still needed for production-readiness it looks promising. I’m hoping to share more details on patterns and approaches over the coming weeks.


