Creating Data Vault Point-In-Time and Dimension tables: merging historical data sources
Edit 2019-09-05: I reviewed this paper on relevance today and made a few minor tweaks. If you are interested in this topic I highly recommend the broader white paper on managing time-variance that I wrote a bit later than this original post. It is called ‘a pattern for Data Mart delivery’ and is available here. This paper builds on the concepts outlined here and also touches on generating PIT, Type 1, 2 – basically any kind of delivery from a Data Vault model.
Merging time-variant data
Beyond creating Hubs, Links and Satellites and current-state (Type 1) views off a Data Vault model, one of the most common requirements is the ability to represent a complete history of changes for a specific business entity (Hub, Link or groups of those). A given Hub on average has 3 or 4 Satellites, and is it useful to see the full history of changes for that specific Hub across all Satellites at the very least.
Merging two or more historised (time-variant) data sources, such as Satellites, reuses Data Warehousing concepts that have been around for many years and in many forms. They can generally be referred to as gaps and islands of time (validity) periods.
This post outlines how merging time-variant data can be applied to Data Vault in order to create Point-In-Time (PIT) and Dimension tables.
The resulting Dimension in this example contains the full history of changes for every attribute – completely ‘Type 2’ in Dimensional Modelling terms. How the history of changes is represented can be customised for individual attributes as well, and this is relatively easy once the base data sets are brought together. For this post I will assume the full Dimension (i.e. all attributes) requires a historical / Type 2 perspective.
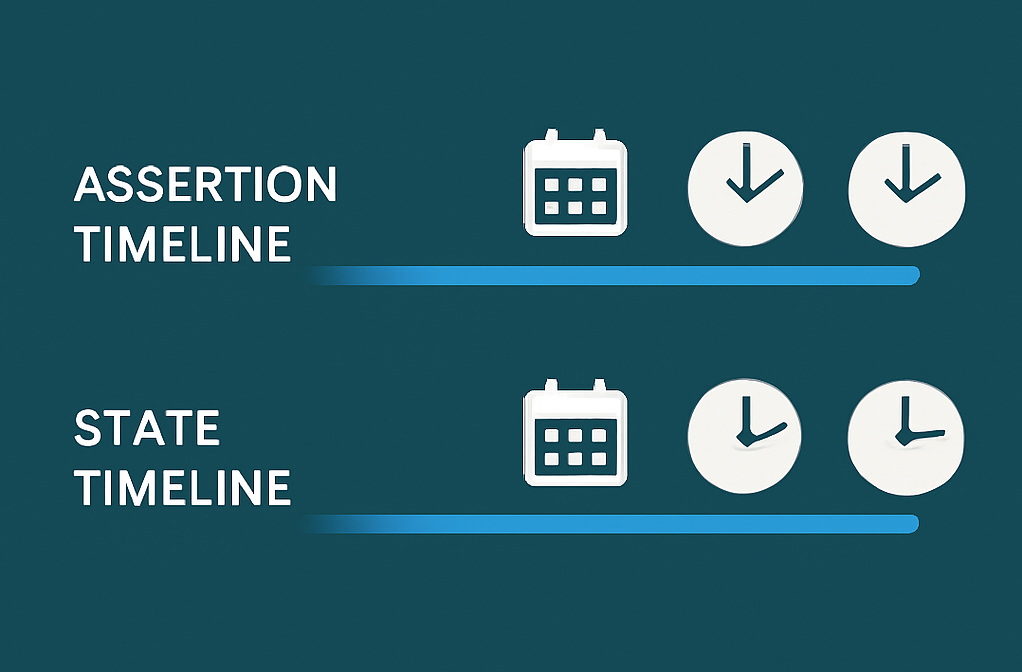
A disclaimer is needed for the PIT tables as well: if you have read any of the Data Vault books you may notice that my interpretation of a PIT table is slightly different. The PIT explanations in the available books are geared towards storing and maintaining snapshots of ‘state’ for data sets at various intervals (e.g. days as per midnight or something like that).\
While this approach fits various use-cases, in this post I will focus more on combining all history from the involved tables at the most detailed level. The reasoning for this is that a ‘state per interval’ snapshot can always be derived from the full history, and by (re)using the same techniques described in this post.
In other words, you can present the PIT snapshot very easily if you have the combined full history of changes available.
The default PIT table is a combination of the various Satellite key and date attributes against the lowest defined grain (the entity, Hub). However, it is perfectly reasonable to add attributes or even business logic if it makes sense for you. In the end, PIT tables are meant as performance enhancers that need to be fit-for-purpose.
As an interesting observation: the more attributes you add to a PIT table, the more the result starts to look like a Dimension (and vice-versa).
To keep some differentiation between the two let’s agree that a PIT table combines history from its direct surrounding tables (all Satellites for a Hub for example). A Dimension is broader than this and can contain more historised sets (e.g. multiple Hubs, Links and their Satellites).
If in any way possible, I always try to generate a Dimensional model directly off the Data Vault and only use PIT tables if there is really a requirement for additional performance. As a result, I don’t really use PIT structures that often. But if you need that bit of additional performance loading a Dimension they may come in handy.
The difference between PIT tables and Dimension tables isn’t really big and the logic to create both is very similar. The main difference is that creating a Dimension table by combining multiple sets of Hubs, Links and Satellites requires some creativity around navigating through the model.
For example: which path to take through the model, preventing cycling back to tables that are already incorporate – that sort of thing. But once you have mapped your path through the model the logic to put the associated time-variant data set together is the same.
I have applied these concepts in the Virtual Data Warehouse software so you can ‘play around’ with generating various time-variant structures. The functionality fort his is available in the ‘delivery’ menu option.
Feel free to download the latest version and try this out yourself, but let’s start with the basics first.
Joining historised data sets together
The basic approach to join two time-variant tables together is to join them on their shared key (CUSTOMER_SK in the example below) as well as their Effective and Expiry Date/Times. This is -by far- the easiest if you have an expiry date/time, of course, but if you don’t want to persist this you can always derive it off the effective date/time. In the example below I persisted the expiry date/time in the available underlying data.
The join logic is essentially making sure the overlap in time-periods (I always refer to this as ‘time slices’) is evaluated: the greatest of the two effective dates is smaller than the smallest of the two expiry dates. Everything else we do is a variation of this theme. Consider the example below:

This query provides you a full history result showing the raw output for a Customer Hub and its two Satellites. The output of this query is displayed below:

The first Effective Date/Time and Expiry Date/Time combination (column 2 and 3) represent the smallest time slices for this set of tables. The other two combinations (columns 4+5 and 6+7) represent how the two Satellites fit in these timelines and the red circles indicate that for a specific ‘most-granular’ time slice there are were no changes for that specific Satellite (repeating of values).
Please note that these data sets have been merged using the ‘OMD_EFFECTVE_DATETIME’, which is a substitute for the Load Date / Time Stamp (LDTS) in this case. The LDTS captures the moment that data has been recorded in the Data Warehouse environment.
In other words: the PIT represents data sets that have been joined together from the perspective of when the records arrived in the Data Warehouse. In any given Data Warehouse there are many perspectives of time to choose from, and the LDTS usually doesn’t represent the reality the business users would expect. Choosing the right timeline to report on for delivery is a major decision that can drastically alter the results. This is explained in more detail in the paper ‘a pattern for Data Mart delivery‘.
This is an example of a basic PIT table, that can be persisted and updated as part of the Data Vault refresh mechanisms. The idea is that this table can be used to INNER JOIN Satellites to retrieve any required attributes for upstream processing. The fact that the complex join logic is already handled, and that an INNER JOIN can be used can make a performance difference.
Of course, some SQL compilers provide GREATEST and LEAST functions that you can use as well as opposed to a CASE statement.
Making joining easier when you have multiple tables in scope
The technique explained in the previous section is geared towards combining two time-variant sources and it is not very straightforward (transparent) to add more time-variant tables using this approach. Of course you can wrap the above logic in a sub-query and merge this with the next time-variant set, but this creates complex logic – especially when handling exceptions such as multi-active Satellites. A better way in my view is to adopt the gaps-and-islands technique again. This basically works as follows:
- The first step is to create a combined set of all available times (Effective Date/Tiems). This is achieved by UNION-ing the Effective Date/Times across all the time-variant tables (data sets) you need and provides you with the smallest (most granular) available time-slices / level of detail. It is recommended to also UNION a zero-record (ghost record) in this step to make sure a complete timeline between ‘earliest history’ and ‘end of calendar’ can be created. This way you don’t even need zero-records in the Satellites!
- The second step is to derive the Expiry Date/Times from the above set, creating a range that can be easily joined against.
- The third step is to join each individual (time variant) table against this range of time-slices and selecting the attributes you want to present. The join uses the same mechanism as above (greatest of the two effective dates < smallest of the two expiry dates) but the big difference is that each time-variant table is joined against the central ‘range’ set, making this a lot easier to configure and extend. Additional tables can be easily added (but will have an impact on the granularity). I also recommend to join in the central Hub to the range because typically you want to add the business key itself here or also make mention of the time-slice invoked by the creation of the business key. A business key may have been created some time before the first context started to appear in Satellites.
An example is provided here, and the result is the same as earlier (although I selected some other attributes). You can see how easy it is to add more tables to join using this structure, and it’s also easy to add or remove attributes.

Are we there yet?
It is important to realise that the ranges / time-slices created provide the most detailed level available: that is all the history available for all attributes between all involved tables. However, the attributes you select as output may not necessarily be directly related to some of the change records. Or, to look at this the other way: the attribute that may have lead to a change being tracked in the Satellite may not be exposed in the SELECT statement.
Depending on which attributes you expose this may lead to duplicates in the end result, but these can easily be handled by adding row condensing similar to the one used in the Satellites. By applying this concept over the top of the above query it is easy to show the historical context for the attributes in scope and very easy to toggle between a Dimension view, a true Point-in-Time (snapshot) or raw changes.
Applying row condensing for PIT or Dimensions can be implemented by creating a checksum across the all attributes except the lowest-granularity (range) Effective Date/Time, and comparing the rows with each other when sorted by Effective Date/Time. If there are no changes between the rows then the row with the higher Effective Date can be discarded (condensed). This is because apparently the change in the Satellite that created the time-slice was not required in this specific output. The query logic is a bit long to paste here, but can be tested in the Virtual EDW app.
The key steps are to:
- From the output of the time-variant query shown in the previous section; create a checksum (I use MD5) across all all attributes excluding the Effective Date/Time for the range.
- Make the checksums available for comparison, for example:
LAG(ATTRIBUTE_CHECKSUM, 1, '-1') OVER(PARTITION BY [HUB_CUSTOMER.CUSTOMER_SK] ORDER BY PIT_EFFECTIVE_DATETIME ASC) AS PREVIOUS_ATTRIBUTE_CHECKSUM
- Filter out records were the checksum is different than the previous checksum (these are the duplicates)
Again, this applies to every scenario where you only select a subset of all available attributes in time-variant tables.
Final thoughts
The above explanation should provide some handles to create your own time-variant output, but there are always other things to be aware of when deploying these solutions. This is especially true in cases where the result is instantiated into a physical table that needs to be periodically refreshed. Without going into too much detail (posts get too long) here are some pointers:
- Updates in Satellites may occur at different times, which can mean that a later Effective Date/Time can be available while another Satellite still needs to be updated. I work in an environment where everything runs continuously, which means that the moment of refresh for a PIT or Dimension may mean some information may still be loaded into some of the Satellites. This is obviously only an issue if you want to process deltas into your PIT or Dimension, but it is good practice to build in delta handling from the start as a full refresh may quickly become too costly. There are a few ways to handle this (good topic for a next post). The solution can be to implement a mechanism that rolls-back some of the rows and re-applies the updated history or to create loading dependencies (not my personal favourite).
- In complex environments the queries may not work in a single pass, but it’s easy to break up the steps into separate ETL processes that each persist their data. This can give the database a bit of breathing space if required.
- As I mentioned earliest in this post I prefer to ‘jump’ from a Data Vault / DWH into a Dimension or other form of Presentation Layer output straight away skipping PIT tables altogether.
Hope this all makes sense!