
Generating DBT ‘ETL’ for Snowflake
In various recent conversations, each time in an entirely different context, the topic of ‘DBT‘ as a easy-to-use data pipeline tool has come up.
This prompted me to have a closer look a few weeks ago, and I really like the concept.
So, I decided to spend some time to define some Virtual Data Warehouse (VDW) code generation patterns to allow the automation of the necessary DBT code / scripts and – as a proof of concept – use these deploy a Virtual Data Warehouse in a Snowflake (cloud) database. Just for fun, and to see if and how things work.
Data Build Tool
DBT stands for ‘Data Build Tool’ and is an effective approach for building data pipelines using simple configuration files and a Command Line Interface.
At a high level, DBT works by defining a project that contains ‘models’ which are SQL files saved in a designated directory. Specific behaviour (e.g. materialisation) can be specified in these model files, but also at project level in the designated configuration file. A project itself references a ‘profile’ which contains connectivity information.
Models can be referenced to each other in order to construct a data transformation pipeline, and these references are used by the tool to derive order of execution and to create a lineage of steps which can be displayed as a graph. It is simple yet versatile.
The fact that everything (i.e. configuration files, model files) are stored in plain text (i.e. not as binaries) means that it’s an easy fit for the VDW code generator. Even better, the fact that a model (through the project) refers to connectivity details stored outside the environment means that the run-time execution (‘generate in database’) is handled outside VDW.
In short, VDW can generate the code and write the output directly as a model file in the designated DBT directory. DBT can then execute this code using the project parameters and profile connections without further manual intervention.
The setup
To run this example, Snowflake, DBT and VDW need to be configured first.
Snowflake configuration
To run this proof of concept I have created two database schemas in a Snowflake database, and entered the corresponding connection details in the DBT profile. These schemas are:
- VDW; a schema that contains a set of sample source tables, a landing (Staging) area and the Persistent Staging Area (PSA).
- VDW_VIEWS; a schema that is meant to contain the Virtual Data Warehouse objects (views).
The sample data set that can be generated from the TEAM application is used for this example. I use this set often for regression testing purposes, so it comes in handy here. For demonstration purposes, I populated the PSA using the regular delta load patterns as used in other examples.
When we start generating views that define the Virtual Data Warehouse, there is some data in the PSA to play with. An example is displayed in the image below.

DBT configuration
In DBT, the following project setup was configured (direct copy from the dbt_project.yml file):
name: 'vdw'
version: '1.0'
profile: 'vdw-snowflake'
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
target-path: "target"
clean-targets:
- "target"
- "dbt_modules"
models:
enabled: true
#materialized: view
vdw:
example:
vdw:
enabled: false
#materialized: view
000_staging:
enabled: false
materialized: view
100_integration:The above shows that in the ‘vdw’ project there are three model directories: ‘example’, ‘000_staging’ and ‘100_integration’. For this demonstration, I have disabled the models in the ‘example’ and ‘000_staging’ directories by setting the enabled flag to ‘false’.
This way, I can run the entire project but only the models in the ‘100_integration’ directory will be compiled and executed by DBT.
VDW configuration
Lastly, it’s time to configure VDW to generate the correct code. For this, the sample TEAM metadata (source-to-target metadata) has already been prepared and made available to VDW.
So, the only thing we need to do is make sure there is a suitable template and that VDW writes the output to the DBT directory that is meant to contain the model files.

The image above shows that VDW has been configured to write the generated output to the ‘100_integration’ directory (output path). Also, I have added a ‘Data Vault Hub 004 View using DBT and Snowflake’ pattern to be configured as template for DBT / Snowflake code generation.
VDW uses the handlebars templating engine and (as of v1.6) the generic interface for Data Warehouse Automation. Using these techniques, it is very straightforward to make the necessary adjustments in one of the existing templates and save this as the new template for DBT and Snowflake.
The template looks as follows:
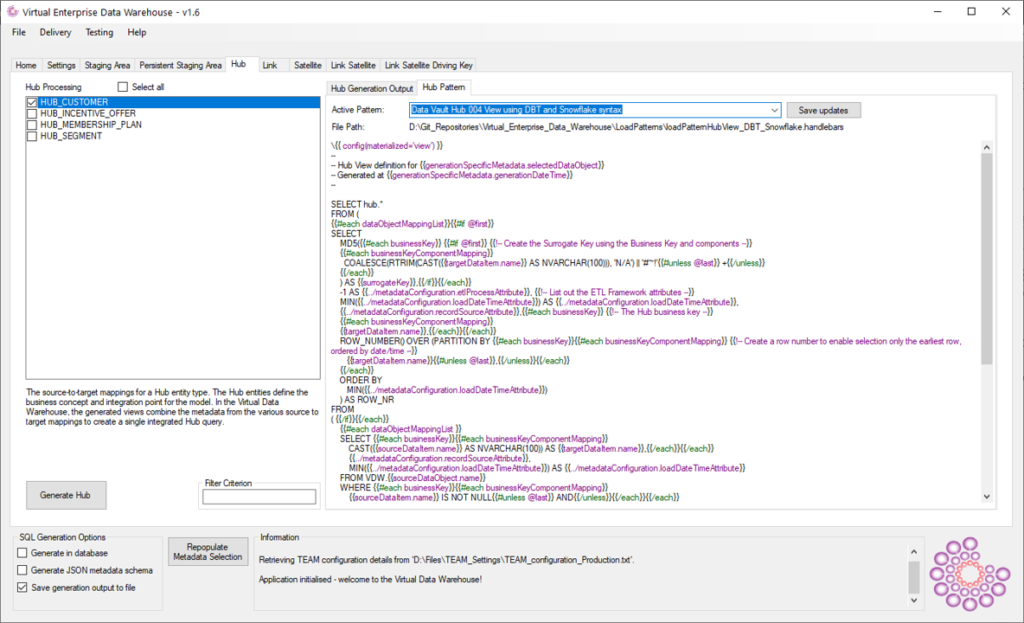
I’ve used an existing SQL Server Data Vault ‘Hub’ template as base, and the changes required to make this compatible to the Snowflake syntax are minimal. Examples of code that was adjusted are changing the ‘HASHBYTES’ function to Snowflake’s ‘MD5’ function, changing ‘ISNULL’ to ‘COALESCE’ and ‘CONVERT’ to ‘CAST AS’.
Also, and most importantly, I have removed the CREATE VIEW syntax – so the expected result is just a SQL SELECT statement.
I also added a DBT specific parameter at the top of the template: {{ config(materialized=’view’) }}. This will inform DBT on model level that the output is to be compiled as a view object. With DBT it also possible to set this parameter at project level, or against specific model directories.
This is how DBT works; by defining models as SELECT statements they can be deployed as views or tables (and some other types) using parameters.
Generating the ETL code
All that is left is to generate and execute the code. First up is to create the model file using the VDW template.
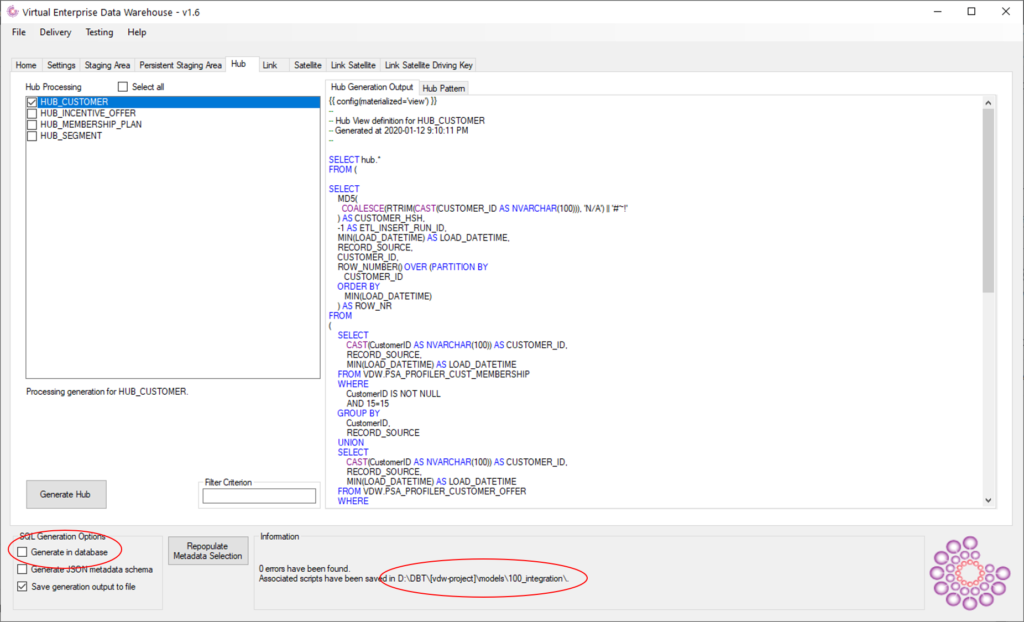
By pressing the ‘generate’ button, VDW generates the code and stores this in the DBT model directory. Note that the ‘generate in database’ checkbox is left unchecked. Connectivity is handled by DBT -by virtue of the profile- and VDW is no longer needed for this. A much cleaner way to go.
As a result, a file ‘HUB_CUSTOMER.sql’ is now created (see below). This file contains the code as shown in the earlier VDW screenshot.

Running the models using DBT
To compile and execute the model in DBT, all that is needed (in its simplest form), is to navigate to the DBT project directory using Powershell or a Command Prompt and execute ‘dbt run’. This will run all models as configured in the project configuration.
Remember, I disabled the ‘example’ and ‘000_staging’ model directories so DBT will only run whatever is stored in the ‘100_integration’ directory.
The ‘run’ command will connect to Snowflake using the profile information and create the view.
Note that ‘view model’ is detected by DBT. This is because of the materialized=view configuration we have generated. This also shows that DBT will take care of the CREATE OR REPLACE syntax at runtime.

Viewing the result
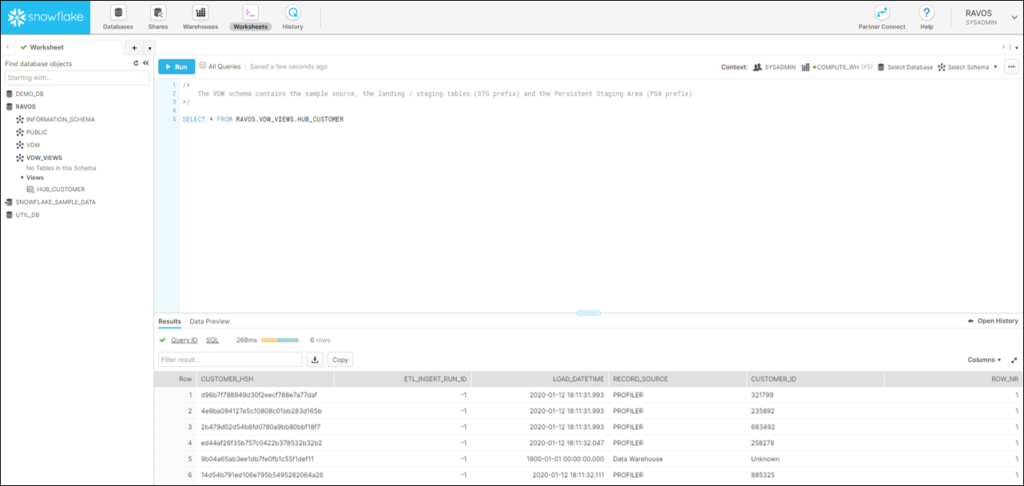
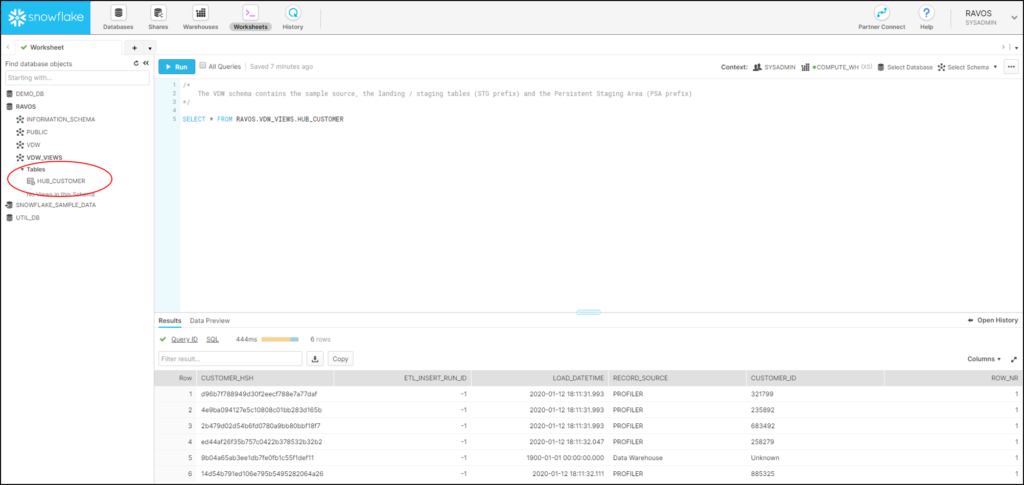
When we look in the Snowflake database, we can see that a view ‘HUB_CUSTOMER’ has indeed been created. A first step towards a Virtual Data Warehouse on Snowflake.
It gets better
A really nice feature of DBT is that, with the end-to-end process now running, you can change the configuration of deployment using either the project configuration or model configuration. If you want to change the view to a table object, all you need to do is to change the configuration from {{ config(materialized=’view’) }} to {{ config(materialized=’table’) }}.
This can, of course, be generated again by VDW but the best approach is to configure this in the DBT project configuration. In any case, when we make this change and run again, DBT detects this and changes the model type to ‘table’.
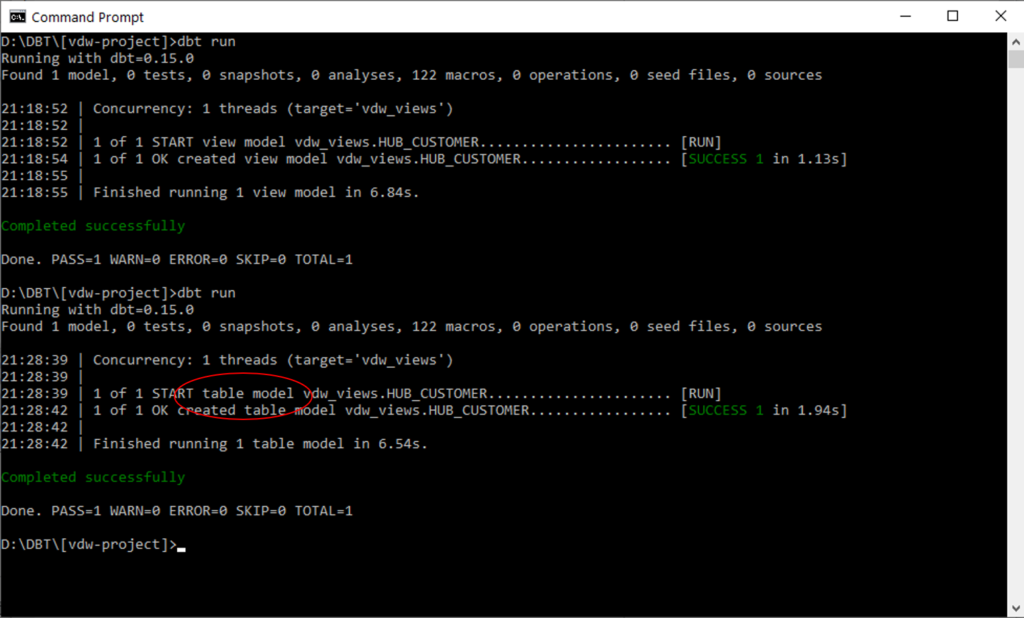
In Snowflake, a Hub Customer table is now created containing the contents we expect. We have essentially materialised the view into a table, and can use DBT’s delta detection / incremental update features to add new rows. Because we have changed the model, the view that was created by DBT earlier has been automatically removed.
Running DBT models this way provides a central set of files to drive deployment, something that fits well in a DevOps or CI/CD approach. It’s something that is worthwhile looking into.
The VDW handlebars template used for this demo is committed to the v1.6 branch on Github for anyone interested. We’re finalising this release now, and expect it to be merged into the master branch in the next few weeks!


