The new version of the data automation metadata schema is ready!
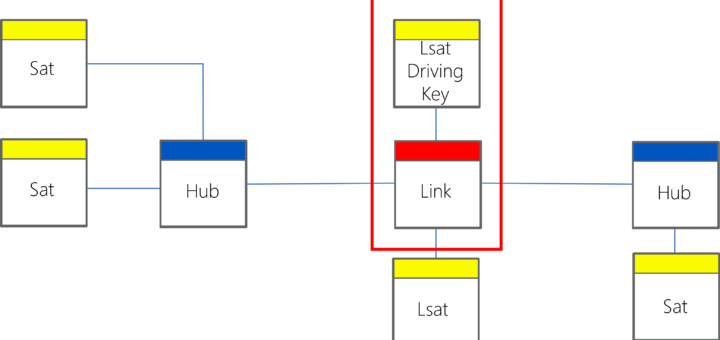
The latest version of the schema for data solution automation has been published on Github. This comprehensive collection includes examples, functions, and definitions crucial for metadata management in data solutions, particularly data warehouse systems. You can find the details, code, and documentation here: What has changed? One significant update focuses on the Business Key Definition. Initially, it featured a property called ‘Business Key Component Mappings,’ which listed data item mappings for various business key components...