
Data Vault ETL Implementation using SSIS: Step 5 – Satellite ETL – part 1 – overview
Satellite processing is one of the types of ETL at the core of implementing Data Vault; this article focuses on the ‘vanilla’ handling of Satellite ETL. Exceptions such as Multi-Active/Multi-Variant implementations (depending on which flavour of Data Vault you use) or isolating Satellites from wide (denormalised) source tables or files will be documented in a separate post.
Satellite processing for Data Vault is in many ways similar to the process that is defined for the Historical Staging ETL process type. The main difference is the option to implement end-dating (expiry date/time) functionality, which is usually recommended for Satellites (not mandatory) and not for Historical Staging tables/ETL. For various reasons including reusability, parallelism and the option to remove the logic altogether, the end-dating functionality has been implemented as a stand-alone (separate) ETL process. This also will be documented in a new post. So for all intents and purposes the default Satellite process explained here can be labelled ‘Insert Only’, but will contain an EXPIRY_DATETIME attribute which will later be used by the end-dating ETL. As end-dating logic is redundant information added for performance reasons this is designed to be potentially removed without impact if required, and can even be virtualised in views or the BI semantic layer.
The Control Flow specifies two separate Data Flows, both of which conceptually are related to the Satellite process but each create their own records:
- Regular Satellite processing (load from the Staging Area)
- Dummy Records creation (handle time-lines), also known as ‘zero-records’
The Data Flow is as follows:
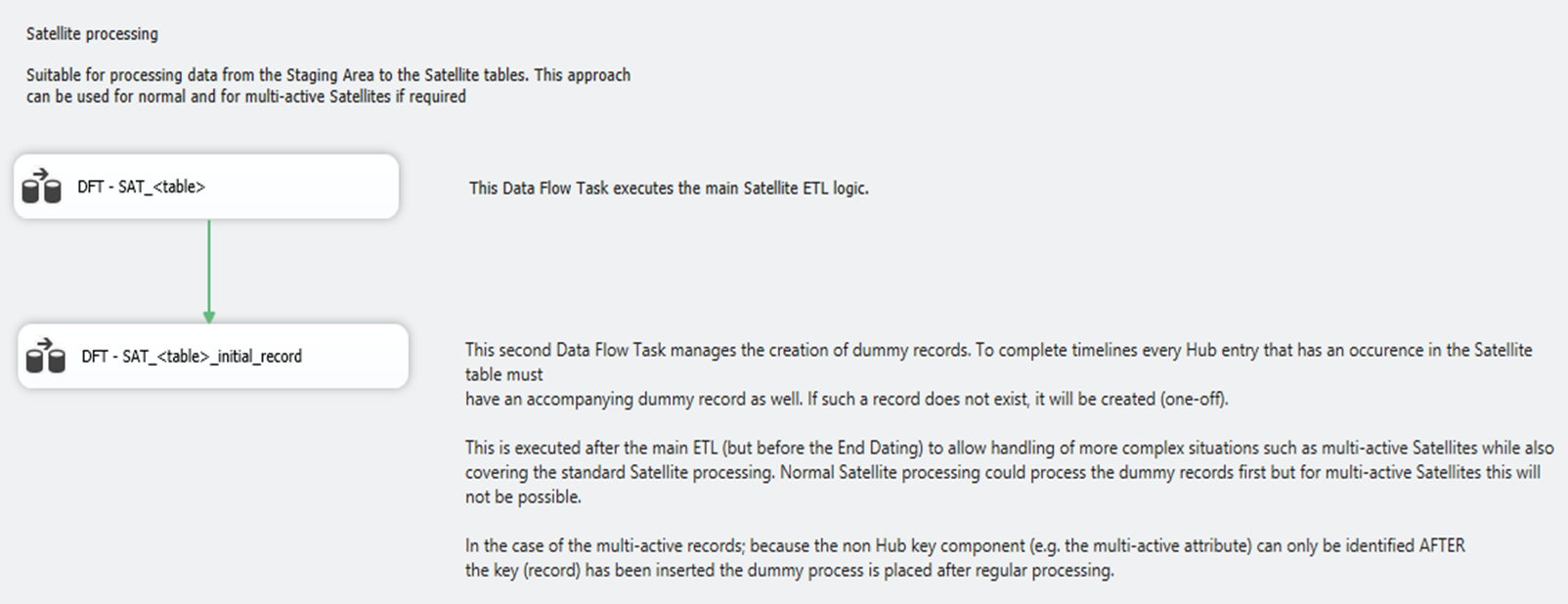
As depicted here the logical ETL process contains two steps. The first step is the regular processing of Satellite data:

- SRC – <STG table>. The direct connection to the Staging Area which has the following characteristics in the selection query:
- Checksum generation; the query also generates a checksum across the attributes that are selected from the Staging Area table, since typically a subset of attributes is required. I typically use SHA1 or MD5 for this
- Distinct selection; because in most cases the attributes selected are a subset of all the attributes in the Staging Area a distinct selection is implemented by default
- Ranking; while SSIS does provide a ranking operation I have embedded a ranking mechanism in the SQL override to be able to detect multiple changes for the same business key. This is important in order to be able to process multiple changes for the same key in a single run. The ranking mechanism is implemented as follows:
ROW_NUMBER() OVER (PARTITION BY <Business Key> ORDER BY <Business Key>, <Event Date/Time>) AS ROW_NUMBER
An example query is as follows:
SELECT DISTINCT
EVENT_DATETIME,
RECORD_SOURCE,
CDC_OPERATION,
<Business Key> -- the identified business key of the source
<Attributes> -- the context attributes that are tracked over time
ROW_NUMBER() OVER (PARTITION BY <Business Key> ORDER BY <Business Key>, EVENT_DATETIME) AS ROW_NUMBER,
<CHECKSUM LOGIC> -- MD5, SHA1 or similar
(
CDC_OPERATION,
<Business Key>
<Attributes>
) AS CHECKSUM
FROM
<Staging Area table>- CNT – Discarded / Inserted / Input. Optional record counts. The counts are stored in local variables and committed to the ETL process metadata after completion of the package execution
- LKP – HUB table. This Lookup operation against the corresponding Hub table is required to obtain the Data Warehouse Key. It is a lookup against only the Business Key
- LKP – SAT table for existing records. This Lookup operation against the target target Satellite table serves as a safety catch to prevent information to be inserted multiple times. It is a lookup against the Natural Key and Event Date/Time. If there is a hit in the lookup the record is discarded (gracefully rejected); otherwise the process will continue (for that record). For performance reasons – it is an extra lookup / cache after all – the record set in the lookup is restricted to only the Hub Key and the Event Date/Time
- CSP – Only lookup the first record for any business key. The Conditional Split verifies the value of the Row Number. If it has value ‘1’ it means that it’s the first change for that Business Key and will need to be compared against the most recent record in the Satellite table. All other records for the same key (other than ‘1’) will be routed directly to the Union without any comparison against existing values, as the Staging Area ETL already covered that these are in fact changes
- LKP – SAT table for checksum comparison. This Lookup operation returns the most recent version of the Hub Key (i.e. maximum Event Date/Time) as well as the checksum for the actual comparison. The join condition can be placed on just the Hub Key as the SQL override already restricts the set to the most recent record for each key
- CSP – Compare Values. The Conditional Split evaluates the Staging and Satellite checksums to define if a change in the records exists. If the checksums are not the same this reflects a change and this leads to an insert into the Satellite target table
- Union All. The purpose of the Union operator (Union All function) is to merge the various data flows for insertion
- DRC – Standard Values. Any proprietary ETL metadata controls and/or values can be set in this Derived Column Transformation. No Data Vault specific values are set
- DST – SAT_<table>. The destination target Satellite table, which is a straight insert of the remaining recordset. Note that this is an insert-only approach (i.e. no end-dating)
The second step in the Data Flow covers the creation of Dummy Records if required:

This process is very simple in design; its purpose is to only insert a dummy record (starting with an effective date of 1900-01-01 or similar) to initiate the timeline for any record that was inserted in the Satellite. The dummy values cover the default values such as ‘Unknown’, ‘Not Applicable’, -1 or similar. The effective date can be set to 1900-01-01 (or similar) and the expiry date (or similar – optional) can be set to 9999-12-31.
There is no requirement to lookup the correct expiry date as the End Dating logic will handle this in its own separate / dedicated ETL process. So, similar to the regular processing this step can be labelled ‘insert-only’. From a design perspective it is recommended to let each Satellite process handle its own dummy records, as opposed to driving this from the Hub process. The reason is that in this approach the Hub ETL does not need to be updated when a new Satellite is added.
An example query to select keys in a Satellite which do not have a dummy record yet is:
SELECT DISTINCT
main.<HUB_SK>
FROM <Satellite Table> main
LEFT OUTER JOIN
(
SELECT
<HUB_SK>,
EFFECTIVE_DATETIME / (same as the EVENT_DATETIME in the source values)
FROM <Satellite Table>
WHERE EFFECTIVE_DATETIME='1900-01-01'
) dummyset
ON main.<HUB_SK>= dummyset.<HUB_SK>
WHERE dummyset.<HUB_SK> IS NULL
Depending on preferences (and performance) this could also be implemented in an Execute SQL Task. This wraps up the overview of how to implement a Data Vault Satellite process using Microsoft SSIS.


