Data Engine Thinking – the book
Data Engine Thinking – the book by Roelant Vos and Dirk Lerner – provides a full and in-depth overview of everything you need to develop a data solution that can stand both the test of time and the real world.

Data solution design patterns, implementation, and automation
Data Engine Thinking – the book by Roelant Vos and Dirk Lerner – provides a full and in-depth overview of everything you need to develop a data solution that can stand both the test of time and the real world.
Announcing Agnostic Data Labs – the new data solution automation platform to truly implemented data warehouse projects your way!
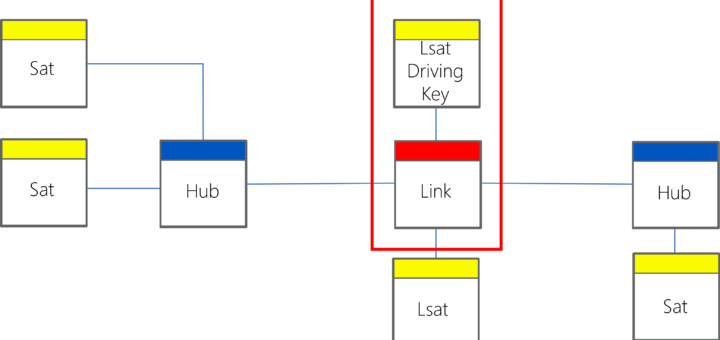
Driving keys continue to cause problems, even for experienced Data Vault practitioners. Are there better ways to manage relationship validity?
End dating Satellites in Data Vault has much more than meets the eye. This post lays out various options and consideration that may help decide whether to implement end-dating, or not.
I would like to share this short blog post with an overview of everything that is happening the data solution automation space. First of all, it’s only a week to go before heading to Europe for various things, including: Working towards these events always pushes the overall content, and there is a lot happening. The design/mapping metadata tool TEAM and code-generation tool VDW are getting a facelift and are being updated to use the v2.0...
The updated (v2.0) version of the data automation metadata schema has been finalised! This version is\ the culmination of many discussions over a long period of time, and hopefully is a step in the direction of making the exchange of data solution / data warehouse metadata easier. The link to the latest & greatest version is here: https://github.com/data-solution-automation-engine/data-warehouse-automation-metadata-schema/releases/tag/v2.0. An important change is that the ‘Data Query’ concept has been split out into a query at...
Joining tables in the Persistent Staging Area (PSA) could be a practical solution that avoids downstream complexities. This post explains the pattern to do so.
By plotting, and then combining, bitemporal and historised data sets on a cartesian plane it’s really easy to understand bitemporal behaviour.
When delivering data from the integration layer (e.g. a Data Vault model) to the presentation layer (anything, but usually a dimensional model or wide table), a key requirement is re-organising data to the selected ‘business’ timeline for delivery.
During this process, we leave the safety of the assertion (technical) timeline behind and start using the real-world state timeline for delivery. This may create some unexpected results!
The data is wrong! No, it’s not wrong, we’re just looking at it from different points in time. This post shows how a data warehouse helps to manage this common topic on data interpretation.
Data Vault / ETL / General
by Roelant Vos · Published February 5, 2023 · Last modified February 7, 2023
When preparing Data Vault content for consumption in a dimensional model, dimension keys can be created to join the resulting fact- and dimension tables in a performant way. But what about for a truly virtual data mart? This post covers approaches to issue dimension keys that are fully deterministic.
More
Data Solution Design Patterns public training x2 - Germany/Switzerland (November 2023)
DVEE Summit (November 2023, Lisbon, Portugal)